What is Wide Column Stores?
As mentioned in my earlier article for Key-Value Stores, wide column stores have tables which contains columns. The small difference is that Wide Column Stores takes a hybrid approach mixing the declarative characteristics game of relational databases with the key-value pair based and totally variables schema of key-value stores. Wide Column databases stores data tables as sections of columns of data rather than as rows of data.
And the way that hybrid works, need to declare so-called column families as part of a reliable schema. But the column families kind of work somewhat like categories of columns, and within a column family we can have different columns in each row. Wide Column Stores are using slight different vocabulary, by calling column families as “Super Columns” and calling tables as “Super Column Families”. The wide-column stores be liable to be the databases that are most foundational at the large business sites.
As written in earlier article about how Dynamo, a key-value store which is widely used at Amazon. And so that’s an exception, but if you take a look at a wide column store called Big Table which is proprietary at Google that Google tends to use with his MapReduce computation engine for working with large datasets. This is best example where we will start understanding why wide column stores are used in these situations at large business sites. Because Big Table and MapReduce are proprietary to Google, but Google also published details of each publically. Yahoo is leading the open-source world together and created an open-source version of MapReduce called Hadoop and an open source of Big Table called HBase. Facebook introduced his own database called Cassandra which is also wide column store database.
Now known the roots of these different databases from these large internet companies and given that they are all matched with MapReduce engines, Cassandra can also be used with Hadoop, these NoSQL databases end up being the databases used in big data applications.
Here are some logos just so you can get visual sense and again map back to this exchange when you came across some of these logos.






And now let’s get a quick diagrammatic sense of how all this works.
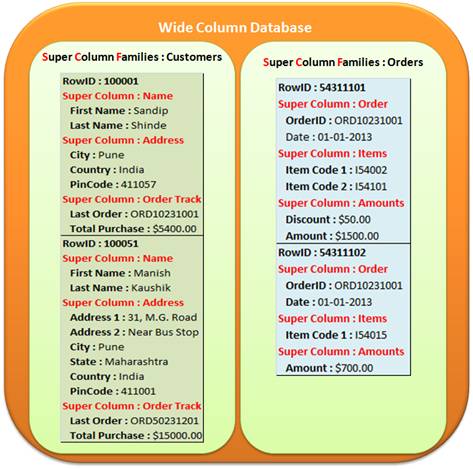
As shown above we have real tables in Wide Column Store and within tables we have rows. In the Key-Value Stores tables called Customers and the columns are almost the same but small difference is every column is a part of a Super Column, that’s why there is super columns called Name, Address and Order Track. If you noticed the second row here has the same schema as the first but there some extra columns added for Super Column Address. So this is again good example of schemaless designing and this is beauty of NoSQL databases. Then we have Super Column Families called Orders and yes again we have done pretty much that same thing here.
I hope all of you understand Wide Column Store Databases very well. In my next and last article of this NoSQL Categories Breakdown I will explain about Graph Databases.
Thanks for your valuable time.
Sandip
Leave a comment
BI Big Data Authors
Our Visitors


Really simple but sensible explanation..thank you..Still I have couple of question about No-SQL..hope you can help me if I asked!!! let me know?